A data scientist is using Spark SQL to import their data into a machine learning pipeline. Once the data is imported, the data scientist performs machine learning tasks using Spark ML.
Which of the following compute tools is best suited for this use case?
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
A)

B)

C)

D)

E)

A machine learning engineer has created a Feature Table new_table using Feature Store Client fs. When creating the table, they specified a metadata description with key information about the Feature Table. They now want to retrieve that metadata programmatically.
Which of the following lines of code will return the metadata description?
A machine learning engineering team has a Job with three successive tasks. Each task runs a single notebook. The team has been alerted that the Job has failed in its latest run.
Which of the following approaches can the team use to identify which task is the cause of the failure?
A data scientist is performing hyperparameter tuning using an iterative optimization algorithm. Each evaluation of unique hyperparameter values is being trained on a single compute node. They are performing eight total evaluations across eight total compute nodes. While the accuracy of the model does vary over the eight evaluations, they notice there is no trend of improvement in the accuracy. The data scientist believes this is due to the parallelization of the tuning process.
Which change could the data scientist make to improve their model accuracy over the course of their tuning process?
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
A machine learning engineer is using the following code block to scale the inference of a single-node model on a Spark DataFrame with one million records:

Assuming the default Spark configuration is in place, which of the following is a benefit of using anIterator?
Which of the following describes the relationship between native Spark DataFrames and pandas API on Spark DataFrames?
A data scientist has created two linear regression models. The first model uses price as a label variable and the second model uses log(price) as a label variable. When evaluating the RMSE of each model bycomparing the label predictions to the actual price values, the data scientist notices that the RMSE for the second model is much larger than the RMSE of the first model.
Which of the following possible explanations for this difference is invalid?
In which of the following situations is it preferable to impute missing feature values with their median value over the mean value?
A machine learning engineer is converting a decision tree from sklearn to Spark ML. They notice that they are receiving different results despite all of their data and manually specified hyperparameter values being identical.
Which of the following describes a reason that the single-node sklearn decision tree and the Spark ML decision tree can differ?
A machine learning engineer would like to develop a linear regression model with Spark ML to predict the price of a hotel room. They are using the Spark DataFrametrain_dfto train the model.
The Spark DataFrametrain_dfhas the following schema:

The machine learning engineer shares the following code block:
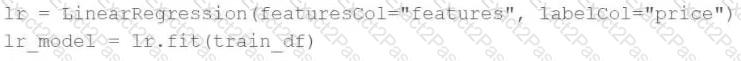
Which of the following changes does the machine learning engineer need to make to complete the task?
A machine learning engineer has been notified that a new Staging version of a model registered to the MLflow Model Registry has passed all tests. As a result, the machine learning engineer wants to put this model into production by transitioning it to the Production stage in the Model Registry.
From which of the following pages in Databricks Machine Learning can the machine learning engineer accomplish this task?
A data scientist has defined a Pandas UDF function predict to parallelize the inference process for a single-node model:

They have written the following incomplete code block to use predict to score each record of Spark DataFramespark_df:

Which of the following lines of code can be used to complete the code block to successfully complete the task?
A new data scientist has started working on an existing machine learning project. The project is a scheduled Job that retrains every day. The project currently exists in a Repo in Databricks. The data scientist has been tasked with improving the feature engineering of the pipeline’s preprocessing stage. The data scientist wants to make necessary updates to the code that can be easily adopted into the project without changing what is being run each day.
Which approach should the data scientist take to complete this task?
Which of the following evaluation metrics is not suitable to evaluate runs in AutoML experiments for regression problems?
Which of the following tools can be used to distribute large-scale feature engineering without the use of a UDF or pandas Function API for machine learning pipelines?
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.
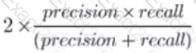
Which of the following suggestions should the team include in their guidelines?
Which of the following tools can be used to parallelize the hyperparameter tuning process for single-node machine learning models using a Spark cluster?